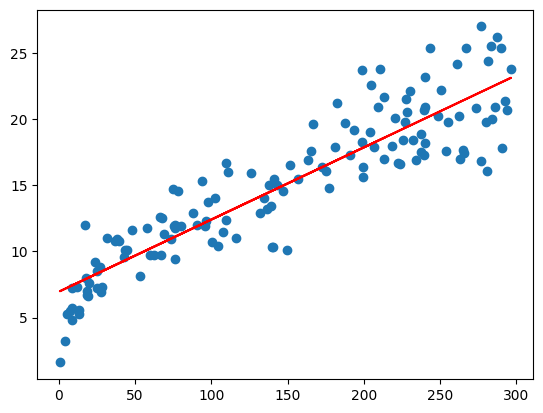
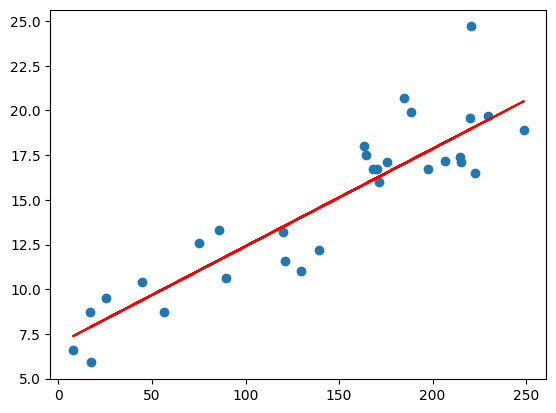
array([[213.4],
[151.5],
[205. ],
[142.9],
[134.3],
[ 80.2],
[239.8],
[ 88.3],
[ 19.4],
[225.8],
[136.2],
[ 25.1],
[ 38. ],
[172.5],
[109.8],
[240.1],
[232.1],
[ 66.1],
[218.4],
[234.5],
[ 23.8],
[ 67.8],
[296.4],
[141.3],
[175.1],
[220.5],
[ 76.4],
[253.8],
[191.1],
[287.6],
[100.4],
[228. ],
[125.7],
[ 74.7],
[ 57.5],
[262.7],
[262.9],
[237.4],
[227.2],
[199.8],
[228.3],
[290.7],
[276.9],
[199.8],
[239.3],
[ 73.4],
[284.3],
[147.3],
[224. ],
[198.9],
[276.7],
[ 13.2],
[ 11.7],
[280.2],
[ 39.5],
[265.6],
[ 27.5],
[280.7],
[ 78.2],
[163.3],
[213.5],
[293.6],
[ 18.7],
[ 75.5],
[166.8],
[ 44.7],
[109.8],
[ 8.7],
[266.9],
[206.9],
[149.8],
[ 19.6],
[ 36.9],
[199.1],
[265.2],
[165.6],
[140.3],
[230.1],
[ 5.4],
[ 17.9],
[237.4],
[286. ],
[ 93.9],
[292.9],
[ 25. ],
[ 97.5],
[ 26.8],
[281.4],
[ 69.2],
[ 43.1],
[255.4],
[239.9],
[209.6],
[ 7.3],
[240.1],
[102.7],
[243.2],
[137.9],
[ 18.8],
[ 17.2],
[ 76.4],
[139.5],
[261.3],
[ 66.9],
[ 48.3],
[177. ],
[ 28.6],
[180.8],
[222.4],
[193.7],
[ 59.6],
[131.7],
[ 8.4],
[ 13.1],
[ 4.1],
[ 0.7],
[ 76.3],
[250.9],
[273.7],
[ 96.2],
[210.8],
[ 53.5],
[ 90.4],
[104.6],
[283.6],
[ 95.7],
[204.1],
[ 31.5],
[182.6],
[289.7],
[156.6],
[107.4],
[ 43. ],
[248.4],
[116. ],
[110.7],
[187.9],
[139.3],
[ 62.3],
[ 8.6]])